
Twentieth in a series of monthly posts from the Dwoskin Project based at the University of Reading
Zoe Bartliff 17 Feb 2021
As a part of The Legacies of Stephen Dwoskin Project, a collaborative team has been exploring the use of visualisations for supporting what we call the archival workflow, something that we are taking further in 2021 with National Archives Testbed funding. The archival workflow addresses the many stages required to take an unordered collection into the archive, assess its contents, and identify any potentially private or otherwise sensitive material, before finally cataloguing and presenting the archive to the public. This is a time-consuming process and even more so for large collections.
Given the increasing prevalence of digital technologies in modern society, it is possible for digital archives such as Dwoskin’s to consist of several million items. This is unfeasible for an archivist to assess effectively, even before confronting the issues of extracting relevant data, such as date of creation, or the placement of the file in relation to others in the collection. Nevertheless, the hard drives were instrumental to Dwoskin’s work from the turn of the millennium onwards, and contain records that relate to the creation of his films, artwork, his unfinished autobiography and a range of more personal items such as his email account.
This makes it important to ensure that, as much as possible, the data that the drives contain can be extracted, examined, and made available for research. The visualisations our team has been exploring are intended to support this process by helping the archivist gain an ‘at-a-glance’ idea of the contents of the collection.
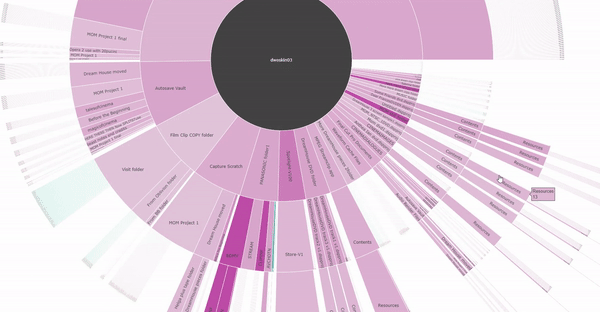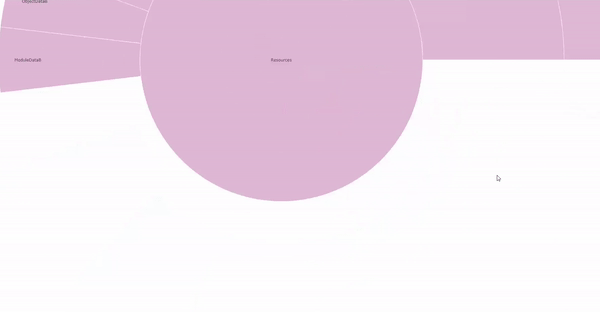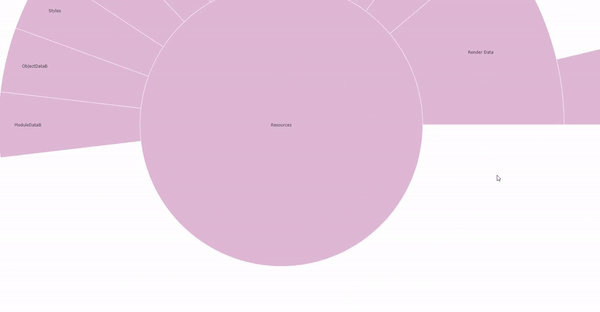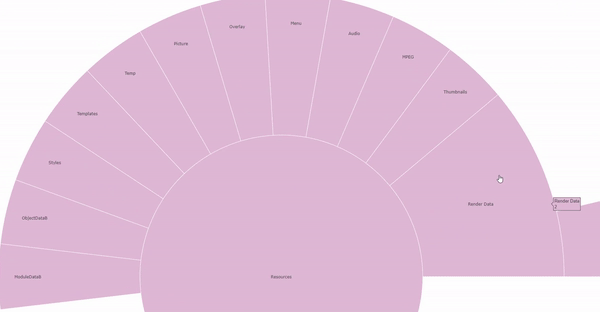
One such visualisation is the sunburst representations of the file directory structure found in Dwoskin’s hard drives. Created using metadata extracted from the drives, the sunburst visualisations capture the file directory structure and present it in a radial hierarchy, with those files on the top level of the drive in the centre and then those within folders at the next level and so on. These visualisations help to demonstrate how the files are ordered within the drive, allowing someone to examine both Dwoskin’s organisational technique and also how files might be grouped together whether by folder or by date. This approach speaks to the archival imperative to preserve the original order of collections, but also the movement seen within modern practice to prioritise a ‘more product, less process’ approach to selection and appraisal.

Visualisations such as these can be an effective method for supporting an archivist to explore, appraise and catalogue the files within a personal digital archive. They can lighten the mental strain and cognitive workload for the archivist by easing the need to recall how a particular record is situated within the collection or relates to the other records. The ‘point-and-click’ interactions are intuitive to use, and support an approach to the investigation of records that mimics the ‘open-the-box-and-take-a-look’ method used for manual appraisal of archive contents. Additionally, the option of including metadata fields through the use of variegated colour, or the hover-over text function, can offer the archivist a balance between gaining an ‘at-a-glance’ idea of the content and their ability to focus on the detail of the records. Combined, these aspects facilitate a more efficient examination of large-scale collections.
In order to disseminate this research, the team submitted and presented a poster presentation to the ASIS&T conference 2020. This poster was well received and won first place in the poster competition. The full poster paper can be found in the conference proceedings and the poster itself is available here.
Featured image: One of Stephen Dwoskin’s hard drives.
XXX
The Dwoskin Project is based at the University of Reading and supported by the AHRC. Visit its website: https://research.reading.ac.uk/stephen-dwoskin/
Zoe Bartliff is a postdoctoral research associate at the University of Glasgow.
Twitter: @ZBartliff, @YunhyongKim
This is a copied post. Original post here
